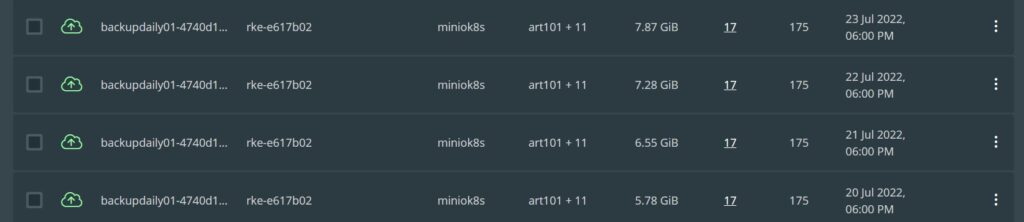
Like any good home IT shop, backups can be a struggle. Those that have visited in the past will note that there were a number of articles published. Sadly, in a fit of poor planning, I nuked my Kubernetes cluster without checking on backups. What was missing was this particular site. There is a lesson here… somewhere…
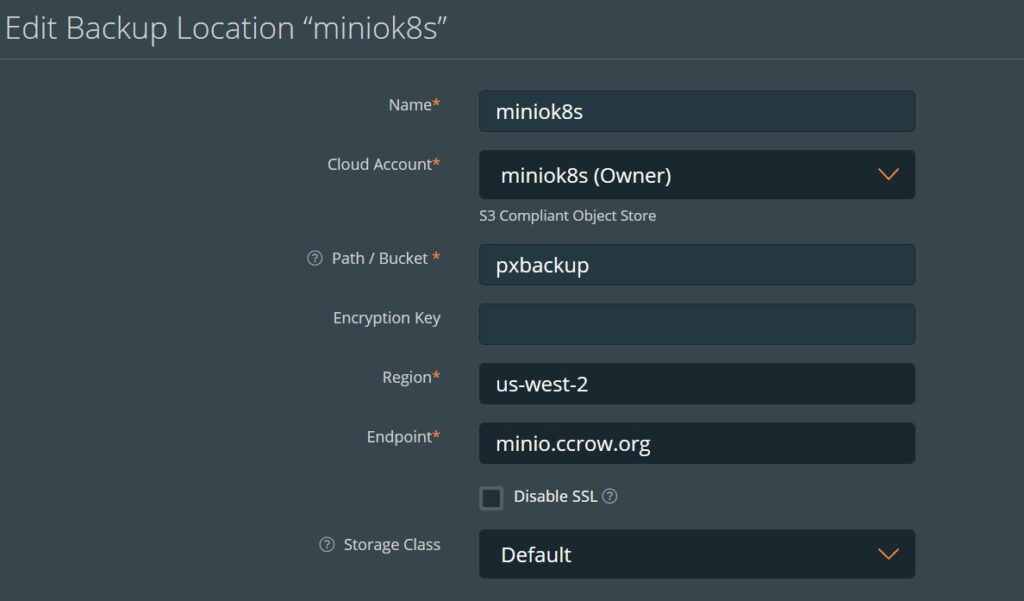
I will mention that the backups I had were Kubernetes native backups (using PX Backup). I did have VM backups, but restoring an entire cluster is a poor way to restore a Kubernetes application
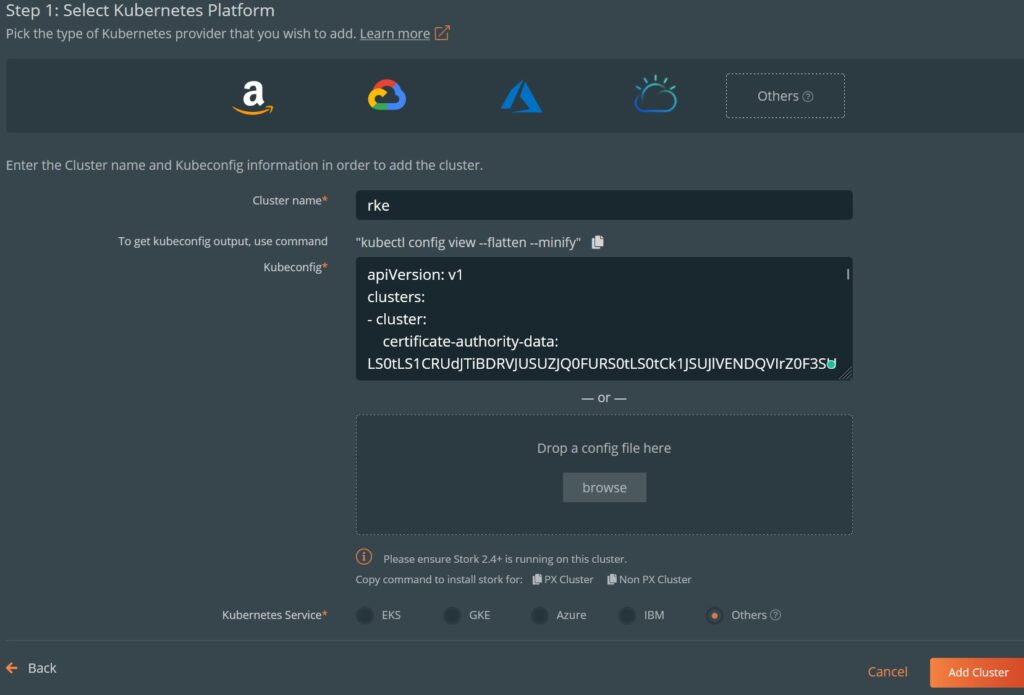
I’m going to shift focus a little and start by walking people through the restoration process for this cluster, and as a way of documenting the rebuild (make a mental note: print this page).
What do we need to get an RKE2 cluster going?
Unlike more manual methods I have used in the past, RKE2 provides an easy way to get up and going and comes out of the box with a few excellent features. For those wanting to use kubeadm, I would suggest this excellent article:
https://tansanrao.com/kubernetes-ha-cluster-with-kubeadm/
For my purposes, I’m going to configure 8 ubuntu 20.04 VMs. Be sure to be comfortable using ssh. I would also recommend a workstation VM to keep configurations and to install some management tools. kubectl for example:
sudo snap install kubectl --classic
As an overview, I have the following VMs:
– lb1 – an nginx load balancer (more on that later)
– rke1 – my first control plane host
– rke2 – control plane host
– rke3 – control plane host
– rke4 – worker node
– rke5 – worker node
– rke6 – worker node
– rke7 – worker node
My goal was to get RKE2, Metallb, Minio, Portworx, PX Backup and Cert-manager running.
For those that use VMware, and have a proper template, consider this powershell snippet:
Get-OSCustomizationNicMapping -OSCustomizationSpec (Get-OSCustomizationSpec -name 'ubuntu-public') |Set-OSCustomizationNicMapping -IPmode UseStaticIP -IpAddress 10.0.1.81 -SubnetMask 255.255.255.0 -DefaultGateway 10.0.1.3
new-vm -name 'rke1' -Template (get-template -name 'ubuntu2004template') -OSCustomizationSpec (Get-OSCustomizationSpec -name 'ubuntu-public') -VMHost esx2.lab.local -datastore esx2-local3 -Location production
Installing the first host (rke1 in my case)
Create a new file under /etc/rancher/rke2 called config.yaml:
token: <YourSecretToken>
tls-san:
- rancher.ccrow.org
- rancher.lab.local
And run the following to install RKE2
sudo curl -sfL https://get.rke2.io |sudo INSTALL_RKE2_CHANNEL=v1.23 sh -
###
###
sudo systemctl enable rke2-server.service
sudo systemctl start rke2-server.service
Starting the service may take a few minutes. Also, notice I’m using the v1.23 channel as I’m not ready to install 1.24 just yet.
We can get the configuration file by running the following:
sudo cat /etc/rancher/rke2/rke2.yaml
This will output a lot of info. Save it to your workstation under ~/.kube/config. This is the default location that kubectl will look for a configuration. Also, be aware that this config file contains client key data, so it should be kept confidential. We have to edit one line in the file to point to first node in the cluster:
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: *****
server: https://127.0.0.1:6443 #Change this line to point to your first control host!
name: default
contexts:
- context:
cluster: default
user: default
name: default
current-context: default
kind: Config
preferences: {}
users:
- name: default
user:
client-certificate-data: ****
client-key-data: *****
Installing the rest of the control hosts
On your second 2 hosts (rke2 and rke3 in my case). Create a new config file:
token: <yourSecretKey>
server: https://rke1.lab.local:9345 #replace with your first control host
tls-san:
- rancher.ccrow.org
- rancher.lab.local
And install with the following:
sudo curl -sfL https://get.rke2.io |sudo INSTALL_RKE2_CHANNEL=v1.23 sh -
###
###
sudo systemctl enable rke2-server.service
sudo systemctl start rke2-server.service
Again, this will take a few minutes.
Installing the worker nodes
Installing the worker nodes is fairly similar to control nodes 2 and 3, but the install command and service we start are different. Create the following file:
token: <yourSecretKey>
server: https://rke1.lab.local:9345 #replace with your first control host
tls-san:
- rancher.ccrow.org
- rancher.lab.local
And install with:
sudo curl -sfL https://get.rke2.io |sudo INSTALL_RKE2_CHANNEL=v1.23 INSTALL_RKE2_TYPE="agent" sh -
###
###
sudo systemctl enable rke2-agent.service
sudo systemctl start rke2-agent.service
That’s It!
Check your work with a quick ‘kubectl get nodes’
Do I really need this many nodes to run applications? No, you could install RKE2 on one host if you wanted. For this article, I wanted to document how I set up my home lab. Additionally, it is a best practice to have highly available control nodes. For my later escapades, it is also required to have 3 worker nodes because of how portworx operates.
Leave a comment with questions and I will update this post.